
今回は、jQueryのような直感的な構文でHTMLを解析できるPythonライブラリ、pyqueryを紹介します。
この記事では、pyqueryの基本的な使い方から、特定のURLからページ内のリンクを絶対URLで一覧出力する具体的なコード例までを解説します。
Webサイトのスクレイピングにぜひ活用してみてください。
- pyqueryの概要
- ライブラリのインストール方法
- pyqueryを使用してWebページ内のリンクを取得するPythonコード
pyqueryとは
pyqueryはPythonのライブラリで、jQueryのような構文を使用してHTMLやXMLドキュメントを解析・操作することができます。
このライブラリは、ウェブスクレイピングやデータ抽出のタスクを簡単に行うために設計されています。内部でlxmlを使用しており、高速なパース性能を持っています。
CSSセレクタを用いて要素を簡単に選択でき、DOM(Document Object Model)の操作も直感的です。また、pyqueryは絶対URLの生成や属性の取得・設定など、多くの便利なメソッドを提供しています。
ライブラリのインストール
コマンドプロンプトで以下のコマンドを実行してpyqueryをインストールできます。
pip install pyquery作成したPythonコード
このPythonプログラムは、ユーザーがコマンドラインで指定したURLをpyqueryでスクレイピングします。
ページ内の全てのリンク(<a>タグ)を取得し、相対URLを絶対URLに変換。最後に、これらの絶対URLをコンソールに一覧で出力します。
コード解説
scrape_links関数を定義:- 引数としてスクレイピング対象のURLを受け取ります。
- pyqueryを使用して指定されたURLのHTMLを取得します。
- 絶対URLを保存するための空のリスト(
absolute_links)を作成します。 - ページ内のすべてのリンク(
<a>タグ)を取得し、それぞれの絶対URLをリストに追加します。
- メインプログラムの実行:
- コマンドラインでユーザーにスクレイピング対象のURLを入力させます。
- 入力されたURLを
scrape_links関数に渡してスクレイピングを実行します。 - 取得した絶対URLを一覧でコンソールに出力します。
作成した全体のソースコード
from pyquery import PyQuery as pq
import urllib.parse
import sys
def scrape_links(url):
# URLからページの内容を取得
d = pq(url=url)
# 絶対URLのリンクを保存するリスト
absolute_links = []
# ページ内のすべてのリンクを取得
for link in d('a'):
link_url = d(link).attr('href')
# 相対URLを絶対URLに変換
absolute_url = urllib.parse.urljoin(url, link_url)
# リストに追加
absolute_links.append(absolute_url)
return absolute_links
if __name__ == "__main__":
# コマンドラインでURLを入力
url = input("スクレイピングするURLを入力してください: ")
# 入力されたURLでスクレイピングを実行
links = scrape_links(url)
# 絶対URLを一覧で出力
for link in links:
print(link)実行結果
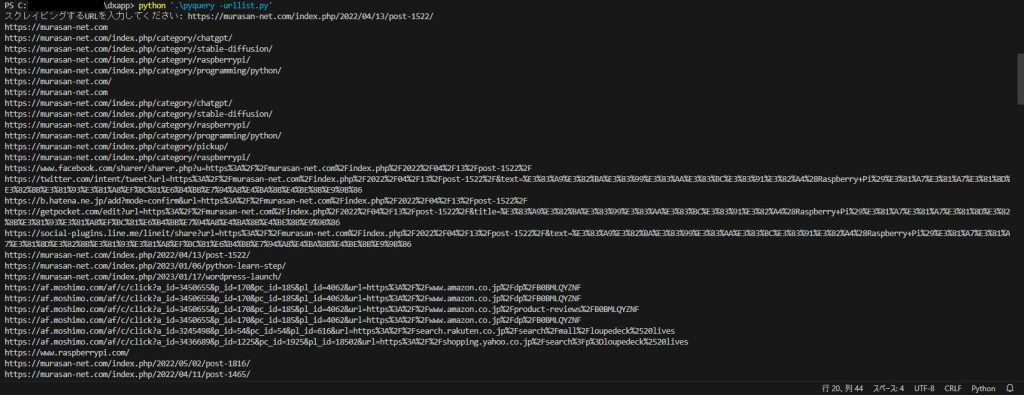
今回は動作テストとして、「ラズベリーパイ(Raspberry Pi)でできること!活用事例集」のページのURLを入力してスクレイピングを行います。
コードを実行すると、コマンドラインで以下のようにURLを聞かれますので、先ほどのページのURLを入力したところ、以下のようにページ内のリンクを一覧で取得することができました。
まとめ
この記事では、pyqueryライブラリの基本的な使い方と、特定のURLをスクレイピングしてページ内のリンクを絶対URLで一覧出力するPythonコードの作成方法を学びました。
pyqueryはその便利さと高速性でウェブスクレイピングの作業を大いに助けてくれます。是非ともこの強力なツールを活用して、効率的なデータ収集を行いましょう。
それでは、また次の記事でお会いしましょう。










コメント