
現代のオフィスワークでは、文書作成の効率化がますます重要になっています。
特に、Microsoft Wordは業務で頻繁に使用されるツールの一つですが、大量のドキュメントを扱う際には、手動での操作が時間を要することがあります。
このような状況でPythonを活用すると、Wordファイルの読み込みや編集作業を自動化し、業務の効率化を図ることができます。
本記事では、Pythonを使ってMicrosoft Wordファイルからテキストデータを自動で抽出する方法について、実践的なコード例を交えながら解説します。
ライブラリのインストール
PythonでWordファイルの内容を読み取るために必要なpython-docxライブラリのインストール方法を解説します。このライブラリは、PythonでMicrosoft Word (.docx) ファイルを読み書きするために使用されます。
ライブラリのインストール手順
python-docx ライブラリをインストールするには、Pythonのパッケージ管理システムであるpipを使用します。コマンドライン(ターミナルやコマンドプロンプト)を開き、以下のコマンドを入力して実行してください。
pip install python-docx作成したPythonコード
このコードは、ユーザーが指定したWordファイルの内容を読み取り、そのテキストをコンソールに表示するためのシンプルなスクリプトです。python-docxライブラリを使用することで、Wordドキュメントの操作が可能になります。
docxライブラリのインポート:docxモジュールをインポートしています。このモジュールは、PythonでMicrosoft Wordファイルを読み書きするために使用します。
read_word_file関数の定義:- Wordファイルからテキストデータを抜き出してコンソールに出力する
read_word_file関数を定義しています。 - 引数
file_pathは、読み込むWordファイルのパスを指定します。
- Wordファイルからテキストデータを抜き出してコンソールに出力する
- Wordファイルの読み込み:
Document(file_path)を使用して、指定されたパスのWordファイルを開きます。Documentオブジェクトを作成し、Wordドキュメントを操作するためのインターフェースを提供します。
- ドキュメント内のテキストの抽出と出力:
doc.paragraphsを使用してドキュメント内の全ての段落にアクセスします。- 各段落(
para)について、para.textプロパティを使用して段落のテキストを取得し、print関数を使ってコンソールに出力します。
- メイン処理の実装:
- スクリプトが直接実行された場合のみ、以下の処理を実行します。
input関数を使用してユーザーにWordファイルのパスを入力させます。入力されたパスはfile_path変数に格納されます。- ユーザーから入力されたファイルパスを
read_word_file関数に渡し、ファイルの内容を読み込んでコンソールに出力します。
全体のソースコード
from docx import Document
def read_word_file(file_path):
"""
Wordファイルからテキストデータを抜き出して出力する。
Args:
file_path (str): 読み込むWordファイルのパス。
"""
# Wordファイルを開く
doc = Document(file_path)
# ドキュメント内の全ての段落をループして、テキストを出力
for para in doc.paragraphs:
print(para.text)
if __name__ == "__main__":
# ユーザーにファイルのパスを入力させる
file_path = input("対象となるWordファイルのパスを入力してください: ")
# 入力されたファイルパスから不要な引用符を削除
file_path = file_path.strip("\"'")
# ファイル読み込みとテキストの出力を実行
read_word_file(file_path)実行結果
ここからは先ほど作成したPythonコードを使用してWordファイルからデータを抽出するテストを行います。
テスト用データ
以下のようにサンプルの文章が入力されてたWrodファイルを用意しました。このファイルを対象にテストを行います。
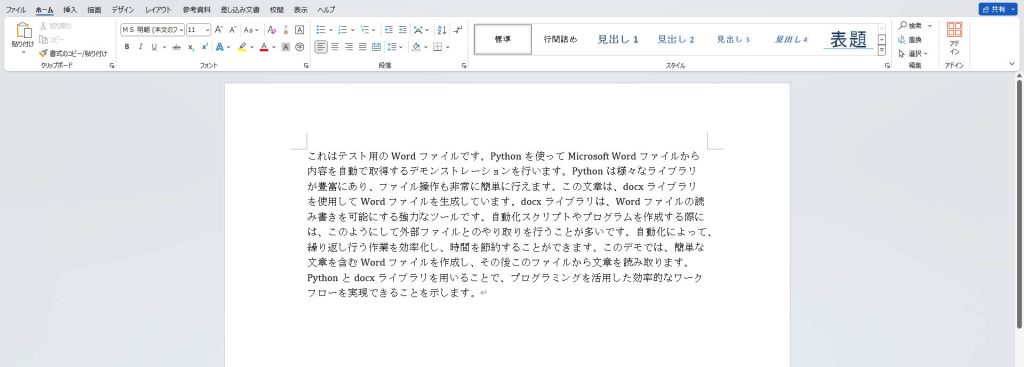
実行結果
作成したPythonファイルを実行すると、以下のように対象となるファイルパスを要求されます。
先ほどのWordファイルのパスを指定します。

仕様通り、Wordファイルの内部の文章を取得することが出ました。
まとめ
この記事では、Pythonとpython-docxライブラリを用いて、Microsoft Wordファイルからテキストデータを抽出する方法を詳細に解説しました。
ユーザーからファイルパスを受け取り、指定されたドキュメントの内容を読み取ってコンソールに出力するシンプルながらも強力なスクリプトを作成しました。
このプロセスを通じて、文書作業の自動化がいかに時間を節約し、効率を向上させるかを理解していただけたことでしょう。
Pythonを活用することで、日常の繰り返し作業から解放され、より創造的なタスクに集中できるようになります。
今回のコード例を出発点として、さらに高度な文書処理の自動化に挑戦してみることをお勧めします。








コメント