
今日のインターネット社会では、様々な情報がWeb上に公開されています。それらの情報を自動的に取得し分析するためには、プログラムを用いてWebページの情報を取得(スクレイピング)する技術が必要となります。
Pythonでは、このようなタスクを簡単に行うことができるモジュールとして requests があります。この記事では、 requests モジュールの get メソッドを使って、特定のURLのページ情報を取得する方法について解説します。
Requestsモジュールとは
Pythonの requests モジュールは、HTTPプロトコルを用いた通信を非常に直感的で簡単に扱うことができるライブラリです。基本的なHTTPメソッド(GET、POST、PUT、DELETEなど)をサポートしており、ヘッダーやクッキーの操作、ファイルのアップロード・ダウンロード、セッションの管理など、HTTP通信に関連する多くの機能を提供しています。
また、 requests モジュールはエラーハンドリングも容易に行えます。例えば、 Response オブジェクトの status_code 属性をチェックすることで、リクエストが成功したかどうかを判断することができます。これにより、HTTP通信のエラーを効率的に管理することが可能です。
このように、 requests モジュールはその使いやすさと柔軟性から、PythonでのHTTP通信を行う際のデファクトスタンダードとも言えるライブラリとなっています。これを用いれば、複雑なHTTP通信も簡潔なコードで実現することができます。
Requestsモジュールのインストール
requests モジュールはPythonの標準ライブラリではないため、使用する前にインストールする必要があります。
ターミナルで以下のコマンドを実行してください。
pip install requestsrequests getメソッドでWebの情報を取得する
requests.get メソッドは、指定したURLに対してHTTP GETリクエストを送信し、サーバーからのレスポンスを取得するために使用されます。このメソッドは Response オブジェクトを返し、これによりレスポンスの本文、ステータスコード、ヘッダーなどの情報を簡単に取得することができます。
import requests
response = requests.get('https://www.example.com')
print(response.text)Response オブジェクト
requests モジュールでHTTPリクエストを送信すると、サーバーからのレスポンスは Response オブジェクトとして返されます。この Response オブジェクトには、HTTPレスポンスに関連する様々な情報が含まれています。
例えば、レスポンスの本文、ステータスコード、ヘッダー情報などを取得することができます。これらの情報は Response オブジェクトのプロパティとしてアクセス可能で、リクエストが成功したかどうかを判断したり、レスポンスの内容を解析したりするために使用します。
- status_code:
- 説明: HTTPレスポンスのステータスコードを返します。例えば、200は成功、404はページが見つからない、500はサーバー内部エラーを表します。
- 使用例:
status_code = response.status_code
- headers:
- 説明: HTTPレスポンスのヘッダーを辞書形式で返します。ヘッダーには、コンテンツタイプ、日付、サーバー名などの情報が含まれます。
- 使用例:
headers = response.headers
- encoding:
- 説明: レスポンスのエンコーディングを返します。このエンコーディングはHTTPヘッダーから推定されます。エンコーディングは、テキストの文字セット(例えば、UTF-8、ISO-8859-1など)を指定します。
- 使用例:
encoding = response.encoding
- text:
- 説明: レスポンスのコンテンツを文字列として返します。エンコーディングは
response.encodingを使用してデコードされます。 - 使用例:
text = response.text
- 説明: レスポンスのコンテンツを文字列として返します。エンコーディングは
- content:
- 説明: レスポンスのコンテンツをバイト形式で返します。これはテキストだけでなく、画像やその他のバイナリデータを取得する際にも使用します。
- 使用例:
content = response.content
作成したPythonコード
このコードは指定したURLにGETリクエストを送信し、レスポンスの各種情報を表示しています。
バイナリコンテンツは output.bin というファイルに保存されます。これは画像や音声など、テキストではないデータを取得したい場合に使います。
import requests
# URLを定義します
url = 'https://www.example.com'
# GETリクエストを送信します
response = requests.get(url)
# ステータスコードを確認します
if response.status_code == 200:
# ステータスコードが200の場合(成功の場合)、レスポンスのテキスト(HTML等)を表示します
print(response.text)
else:
# ステータスコードが200以外の場合(エラーの場合)、エラーとステータスコードを表示します
print("Error:", response.status_code)
# レスポンスヘッダーを表示します
print("Headers:", response.headers)
# レスポンスのエンコーディングを表示します
print("Encoding:", response.encoding)
# レスポンスのバイナリコンテンツを取得し、それをファイルに保存します
# ここでは 'output.bin' という名前のファイルに保存しています
with open('output.bin', 'wb') as f:
f.write(response.content)Pythonコードの実行結果
対象ページ
先ほど作成したプログラムを私が運営しているサイトの以下のURLを指定して実行してみました。

実行結果
実行した結果、以下のように情報を取得することができました。
Headers: {'Server': 'nginx', 'Date': 'Mon, 10 Jul 2023 04:48:37 GMT', 'Content-Type': 'text/html; charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'X-Powered-By': 'PHP/7.4.33', 'X-Pingback': 'https://murasan-net.com/xmlrpc.php', 'Vary': 'User-Agent', 'Link': '<https://murasan-net.com/index.php/wp-json/>; rel="https://api.w.org/", <https://murasan-net.com/index.php/wp-json/wp/v2/posts/10611>; rel="alternate"; type="application/json", <https://murasan-net.com/?p=10611>; rel=shortlink'}
Encoding: UTF-8content プロパティから取得してファイルに保存されたデータは以下の通りです。
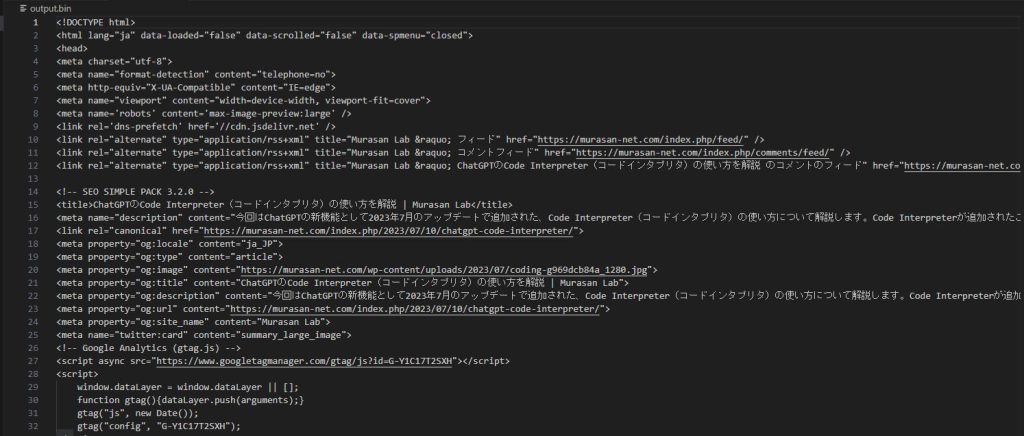
まとめ
Pythonの requests モジュールの get メソッドを用いたWebページ情報の取得方法について解説しました。
requests モジュールはその直感的なインターフェースと豊富な機能により、HTTP通信を行うPythonプログラムの中で広く使われています。
今回学んだ get メソッドと Response オブジェクトの活用により、さまざまなWebサイトから情報を効率的に取得し、それを利用したデータ分析や情報収集が可能になります。Pythonと requests モジュールを使って、自動化の世界をさらに探索してみてください。










コメント