
ウェブスクレイピングは、ウェブページから情報を抽出する強力なツールです。
しかし、ウェブページのHTML構造は複雑で、特定の情報を探すのは一筋縄ではいきません。そこで役立つのが、PythonのライブラリであるBeautifulSoupです。
BeautifulSoupを使用すると、HTMLタグ、id、class情報を指定してデータを効率的に取得することができます。この記事では、BeautifulSoupを使用してHTMLタグ、id、class情報を指定してデータを取得する方法について詳しく解説します。
BeautifulSoupとは
BeautifulSoupの基本的な使い方については、以下の記事で解説しています。

ライブラリのインストール
今回作成するPythonコードの実行に必要なライブラリをインストールします。
ターミナルで以下のコマンドを実行してください。
pip install requests beautifulsoup4HTMLからの抽出方法
今回紹介する方法は、BeautifulSoupオブジェクトのfindメソッドとfind_allメソッドを使用して、Webページから情報を取得します。
- findメソッド:
findメソッドは、BeautifulSoupオブジェクトが解析したHTMLデータから、指定したタグの最初の出現を探します。
このメソッドは、タグ名、属性、属性の値などを指定して検索することができます。例えば、soup.find('div')は最初のdivタグを返し、soup.find(id='content')はid属性が’content’である最初のタグを返します。このメソッドは、指定したタグが見つからない場合はNoneを返します。 - find_allメソッド:
find_allメソッドは、BeautifulSoupオブジェクトが解析したHTMLデータから、指定したタグのすべての出現を探します。
このメソッドも、タグ名、属性、属性の値などを指定して検索することができます。例えば、soup.find_all('div')はすべてのdivタグをリストとして返し、soup.find_all(class_='highlight')はclass属性が’highlight’であるすべてのタグをリストとして返します。このメソッドは、指定したタグが見つからない場合は空のリストを返します。
これらのメソッドを使用することで、HTMLデータから特定のタグの情報を効率的に抽出することができます。
また、これらのメソッドは、タグのネスト(入れ子)構造を考慮した検索もサポートしています。例えば、soup.find('div', {'class': 'container'}).find_all('li')のように、特定のdivタグの中からすべてのliタグを探すことも可能です。
HTMLタグを指定して取得する
1つ目の例では、HTMLのtitile、h2、liタグを指定して、情報を取得する方法について解説します。
titleタグ: titleタグは、HTML文書のタイトルを定義します。このタイトルは、ウェブブラウザのタブやウィンドウのタイトルバーに表示されます。また、検索エンジンの結果ページでページのタイトルとして表示されるため、SEO(検索エンジン最適化)において重要な役割を果たします。titleタグは、headタグの中に配置されます。
<head>
<title>This is the Page Title</title>
</head>h2タグ: h2タグは、HTML文書のセクション見出しを定義します。h1からh6までの見出しタグがあり、h1が最も重要で、h6が最も重要でないとされます。h2は、主要なセクション見出しによく使用されます。見出しタグは、ウェブページの構造を理解するのに役立ち、SEOにも影響を与えます。
<h2>This is a Section Heading</h2>liタグ: liタグは、リスト項目を定義します。通常、ulタグ(順序なしリスト)またはolタグ(順序付きリスト)の中に配置されます。各liタグは、リストの一項目を表します。
<ul>
<li>This is a list item</li>
<li>This is another list item</li>
</ul>コード解説
- ライブラリのインポート:
requestsとBeautifulSoupというPythonライブラリをインポートします。これらは、ウェブサイトからデータを取得し、HTMLデータを解析するために必要です。 - URLの指定: スクレイピングしたいウェブページのURLを指定します。
- データの取得:
requests.get(url)を使用して指定したURLからHTMLデータを取得します。 - HTMLデータの解析:
BeautifulSoup(response.text, 'html.parser')を使用して、取得したHTMLデータを解析します。 - titleタグの取得:
soup.find('title')を使用してHTMLデータからtitleタグの情報を取得します。 - h2タグの取得:
soup.find_all('h2')を使用してHTMLデータからすべてのh2タグの情報を取得します。 - liタグの取得:
soup.find_all('li')を使用してHTMLデータからすべてのliタグの情報を取得します。 - タグ情報の出力: 取得した各タグのテキスト情報を出力します。これにより、指定したウェブページのtitle、h2、およびliタグの内容を確認することができます。
作成したPythonコード
# 必要なライブラリをインポートします
import requests
from bs4 import BeautifulSoup
# スクレイピングしたいURLを指定します
url = "https://www.example.com" # ここにスクレイピングしたいURLを入力してください
# URLからデータを取得します
response = requests.get(url)
# BeautifulSoupオブジェクトを作成します
soup = BeautifulSoup(response.text, 'html.parser')
# titleタグの情報を取得します
title = soup.find('title')
print(f"Title: {title.text}")
# h2タグの情報を取得します
h2_tags = soup.find_all('h2')
for i, h2 in enumerate(h2_tags, start=1):
print(f"H2 tag {i}: {h2.text}")
# liタグの情報を取得します
li_tags = soup.find_all('li')
for i, li in enumerate(li_tags, start=1):
print(f"LI tag {i}: {li.text}")実行結果
今回は例として以下のページを指定してスクレイピングを行いました。
実行結果は以下のように情報を取得することができました。
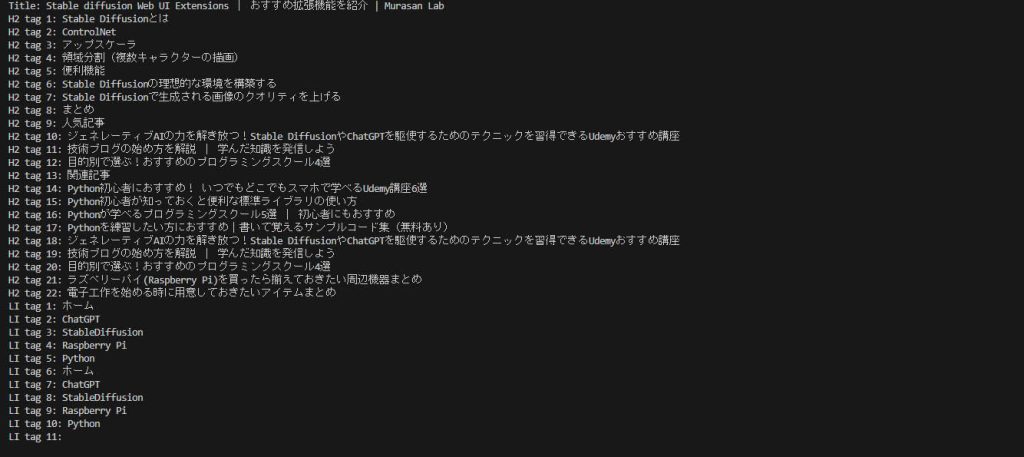
id属性を指定して取得する
id属性は、HTML要素に一意の識別子を付与するために使用されます。id属性の値は、同一のHTML文書内で一意でなければならず、つまり同じidを持つ要素は1つだけでなければなりません。これにより、特定の要素を直接指定したり、JavaScriptやCSSで特定の要素を操作したりすることが可能になります。
例えば、以下のようにHTML要素にid属性を指定することができます:
<div id="header">This is the header section.</div>コード解説
- ライブラリのインポート:
requestsとBeautifulSoupというPythonライブラリをインポートします。これらは、ウェブサイトからデータを取得し、HTMLデータを解析するために必要です。 - URLの指定: スクレイピングしたいウェブページのURLを指定します。
- データの取得:
requests.get(url)を使用して指定したURLからHTMLデータを取得します。 - HTMLデータの解析:
BeautifulSoup(response.text, 'html.parser')を使用して、取得したHTMLデータを解析します。 - idが”content”である要素の取得:
soup.find(id="content")を使用してHTMLデータからidが”content”である要素の情報を取得します。 - 取得した要素の出力: 取得した要素の情報を出力します。これにより、指定したウェブページのidが”content”である要素の内容を確認することができます。
以上が、このPythonコードの処理内容の解説です。このコードを使用することで、ウェブページから特定のidを持つ要素の情報を効率的に抽出することが可能になります。
作成したPythonコード
# 必要なライブラリをインポートします
import requests
from bs4 import BeautifulSoup
# スクレイピングしたいURLを指定します
url = "https://murasan-net.com/index.php/2023/07/20/stable-diffusion-web-ui-extensions-summary/"
# URLからデータを取得します
response = requests.get(url)
# BeautifulSoupオブジェクトを作成します
soup = BeautifulSoup(response.text, 'html.parser')
# idが"content"である要素を取得します
content_id = soup.find(id="content")
print(f"Element with ID 'content': {content_id}")実行結果
今回は例として以下のページを指定してスクレイピングを行いました。
実行結果は以下のように情報を取得することができました。
class属性を指定して取得する
class属性は、HTML要素に一つまたは複数のクラス名を付与するために使用されます。class属性の値は、同一のHTML文書内で複数の要素が共有できます。これにより、同じスタイルルールを適用するためのグループを作ったり、JavaScriptで特定のグループの要素を一括で操作したりすることが可能になります。
例えば、以下のようにHTML要素にclass属性を指定することができます:
<div class="highlight">This text is highlighted.</div>
<p class="highlight">This paragraph is also highlighted.</p>コード解説
- ライブラリのインポート:
requestsとBeautifulSoupというPythonライブラリをインポートします。これらは、ウェブサイトからデータを取得し、HTMLデータを解析するために必要です。 - URLの指定: スクレイピングしたいウェブページのURLを指定します。
- データの取得:
requests.get(url)を使用して指定したURLからHTMLデータを取得します。 - HTMLデータの解析:
BeautifulSoup(response.text, 'html.parser')を使用して、取得したHTMLデータを解析します。 - classが”l-content l-container”である要素の取得:
soup.find_all(class_="l-content l-container")を使用してHTMLデータからclassが”l-content l-container”である要素の情報を取得します。 - 取得した要素の出力: 取得した要素の情報を出力します。これにより、指定したウェブページのclassが”l-content l-container”である要素の内容を確認することができます。
以上が、このPythonコードの処理内容の解説です。このコードを使用することで、ウェブページから特定のclassを持つ要素の情報を効率的に抽出することが可能になります。
作成したPythonコード
# 必要なライブラリをインポートします
import requests
from bs4 import BeautifulSoup
# スクレイピングしたいURLを指定します
url = "https://murasan-net.com/index.php/2023/07/20/stable-diffusion-web-ui-extensions-summary/"
# URLからデータを取得します
response = requests.get(url)
# BeautifulSoupオブジェクトを作成します
soup = BeautifulSoup(response.text, 'html.parser')
# classが"l-content l-container"である要素を取得します
content_class = soup.find_all(class_="l-content l-container")
for i, content in enumerate(content_class, start=1):
print(f"Element with class 'l-content l-container' {i}: {content}")実行結果
今回は例として以下のページを指定してスクレイピングを行いました。
実行結果は以下のように情報を取得することができました。
まとめ
今回は、BeautifulSoupを使用してHTMLタグ、id、class情報を指定してデータを取得する方法について解説しました。
これらのテクニックを使用することで、ウェブページから必要な情報を効率的に抽出することができます。
ウェブページのHTML構造はページごとに異なるため、具体的なタグ、id、classを指定して要素を取得する際には、対象のウェブページのHTML構造を事前に確認することが重要です。これらのポイントを押さえて、ウェブスクレイピングを有効に活用しましょう。










コメント