
インターネットネット上で様々な情報が入手できる現在では、ウェブスクレイピングはデータ駆動型の意思決定を行うための重要なツールとなっています。
PythonとそのライブラリであるBeautifulSoupを使用すれば、ウェブページから必要な情報を効率的に抽出することが可能です。
この記事では、BeautifulSoupを使用してウェブページからHTML全体を取得する基本的なプログラムについて解説します。
BeautifulSoupとは
BeautifulSoupは、Pythonのライブラリで、ウェブスクレイピング(ウェブページからデータを抽出すること)を容易に行うためのツールです。
HTMLやXMLドキュメントを解析し、その構造をPythonのオブジェクトとして扱うことができます。これにより、タグ名や属性、CSSセレクタなどを指定して特定の要素を抽出したり、テキスト内容を取得したりすることが可能になります。
また、ドキュメントの構造を変更したり、新たな要素を追加したりすることもできます。その使いやすさから、ウェブスクレイピングの初心者から経験者まで幅広く利用されています。
ライブラリのインストール
ライブラリのインストール手順を解説します。
まず、BeautifulSoupで解析するデータをURLから取得するのに必要なrequestsモジュールをインストールします。
pip install requests続いてBeautifulSoupをインストールします。
pip install beautifulsoup4作成したPythonコード
今回は指定されてURLのページのHTMLを取得するPythonコードを作成しました。
コード解説
- 必要なライブラリをインポートします。このプログラムでは、ウェブページからデータを取得するための
requestsライブラリと、HTMLを解析するためのBeautifulSoupライブラリを使用します。 get_htmlという関数を定義します。この関数は、引数としてURLを受け取り、そのURLのウェブページからHTMLを取得します。具体的には、requests.get(url)を使用してURLからデータを取得し、そのレスポンスをBeautifulSoupオブジェクトに変換します。このBeautifulSoupオブジェクトは、HTML全体を表現しています。get_html関数は、ウェブページからのデータ取得が成功した場合(HTTPステータスコードが200の場合)にはBeautifulSoupオブジェクトを返し、データ取得が失敗した場合にはエラーメッセージを出力してNoneを返します。- スクレイピングするURLを指定します。このURLは
get_html関数の引数として使用されます。 get_html関数を呼び出してHTMLを取得し、その結果をprint文で出力します。このprint文により、取得したHTML全体がコンソールに出力されます。
作成した全体のPythonコード
作成した全体のソースコードは以下の通りです。
# 必要なライブラリをインポートします
import requests
from bs4 import BeautifulSoup
def get_html(url):
# URLからデータを取得します
response = requests.get(url)
# ステータスコードが200(成功)の場合のみ処理を行います
if response.status_code == 200:
# BeautifulSoupオブジェクトを作成します
soup = BeautifulSoup(response.text, 'html.parser')
# BeautifulSoupオブジェクト(HTML全体)を返します
return soup
else:
print('Failed to get data from the URL. Status code:', response.status_code)
return None
# スクレイピングするURLを指定します
url = 'https://www.example.com' # ここにスクレイピングしたいURLを入力してください
# get_html関数を使用してHTMLを取得し、print文で出力します
html = get_html(url)
if html is not None:
print(html)実行結果
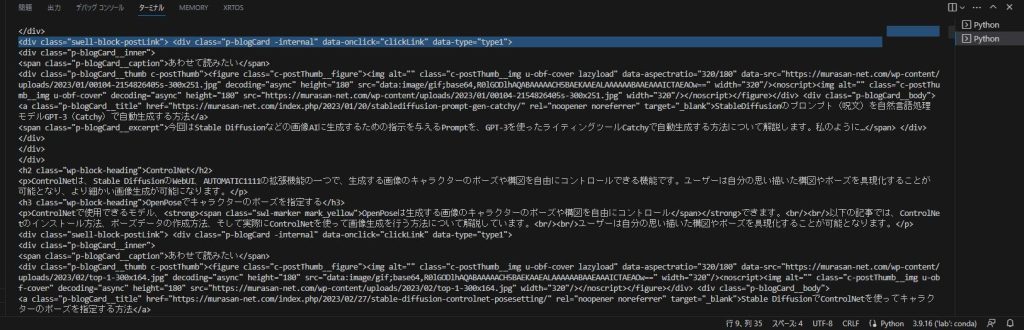
今回は私が公開しているブログの記事である「Stable diffusion Web UI Extensions | おすすめ拡張機能を紹介」のページを対象にスクレイピングを行いました。
先ほど掲載したコードを実行した結果、以下のようにHTMLのコードを取得できました。
まとめ
この記事では、PythonとBeautifulSoupを使用してウェブページからHTMLを取得する基本的なプログラムを作成し、その動作を詳しく解説しました。
BeautifulSoupは、その使いやすさと強力な機能により、ウェブスクレイピングの初心者から経験者まで幅広く利用されています。この基本的なプログラムをスタートポイントとして、より複雑なウェブスクレイピングのタスクに挑戦してみてください。










コメント